はじめに
簡潔に。百均イヤホンからいい音を流したい。
百均イヤホンを一度でも使ったことがある人ならわかると思いますが、どんな良音もAMラジオみたいな音にしてしまうんですよね、、、もう逆にすごい。
で高音質化しようと思ってこんなサイトを見つけた
100均イヤホンを高音質化してくれる無料アプリ (2019年2月23日) - エキサイトニュース
高音質で音楽を楽しむために、高級 イヤホン を使っているという人も多いでしょう。しかし ...
いいんだけど、個体差とか左右の音圧の差を補正できない!!
これでは究極の高音質化を達成できません。
そこで思ったのですが、百均イヤホンが元の音源をどのように劣化させるかをモデル化できれば、百均イヤホンからハイレゾ音源(比喩)を出すことができるのではないかと。
僕が思うに百均イヤホンの音質の悪さの原因は
- 周波数ごとの音量が一定でない(低音だけ異常に音が大きいとか)
- 左右で音圧が違う
- 一定の周波数で共振して倍音が発生している
この三つではないかという仮説のもと色々実験していきます。
準備
まず、イヤホンの周波数特性を測定します。イヤホンの周波数特性を巷ではF特というらしいですが、それ専用の測定器なんて持ってないので自作します。
用意したもの
・SONYのコンデンサーマイク ECM-SP10
・適当な金属の円筒スペーサー
・USBのオーディオインターフェース
・百均イヤホン
・いい音(と思う)が出るイヤホン
マイクがイヤホンジャックを占有してしまうため、新たにUSBインターフェースを買いましたが、環境によっては必要ないかもしれません。
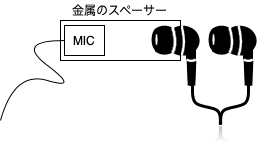
↓作ったのはこんな感じ

百円イヤホンのためにこの時点で3000円ぐらい飛んでいきました。これを人は本末転倒と言う。
測定ソフトの作成
測定の目的はあくまで百均イヤホンを高音質化することなので、この目的に合ったソフトをPythonで作りたいと思います。やりたいことは下記の通り。
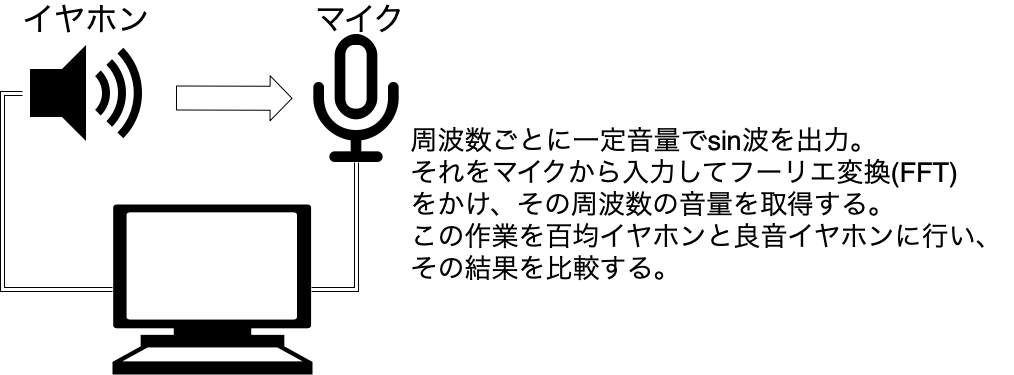
マイクの周波数特性やPC(iMac late2013)のオーディオ入力の特性は不明ですが、百均イヤホンといい音イヤホンとの対照実験とすることで、この問題はクリアできた、はず笑。
作ったソフトのUIはこんな感じです。PyQtとQtDesignerを使ってGUIを作成しました。
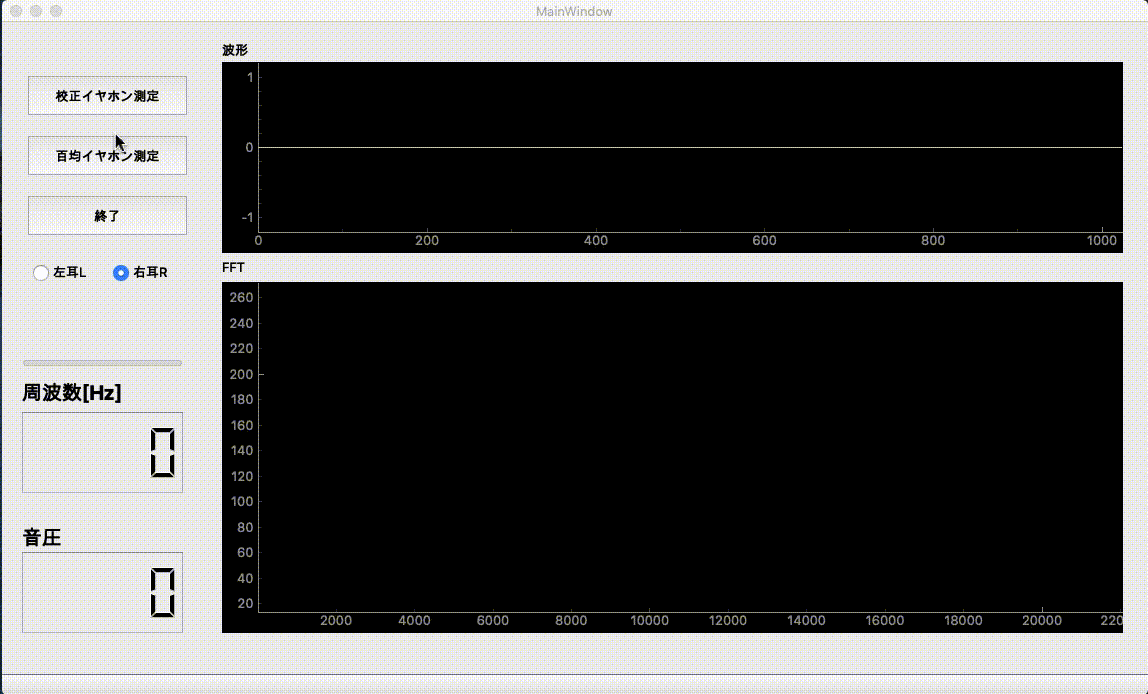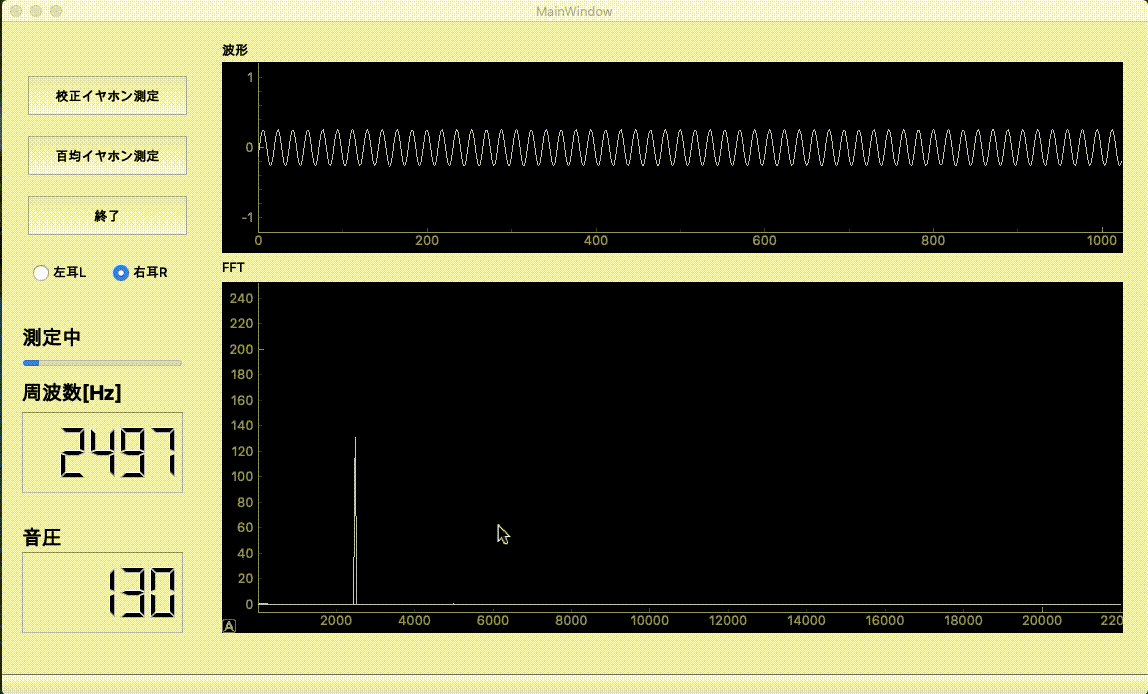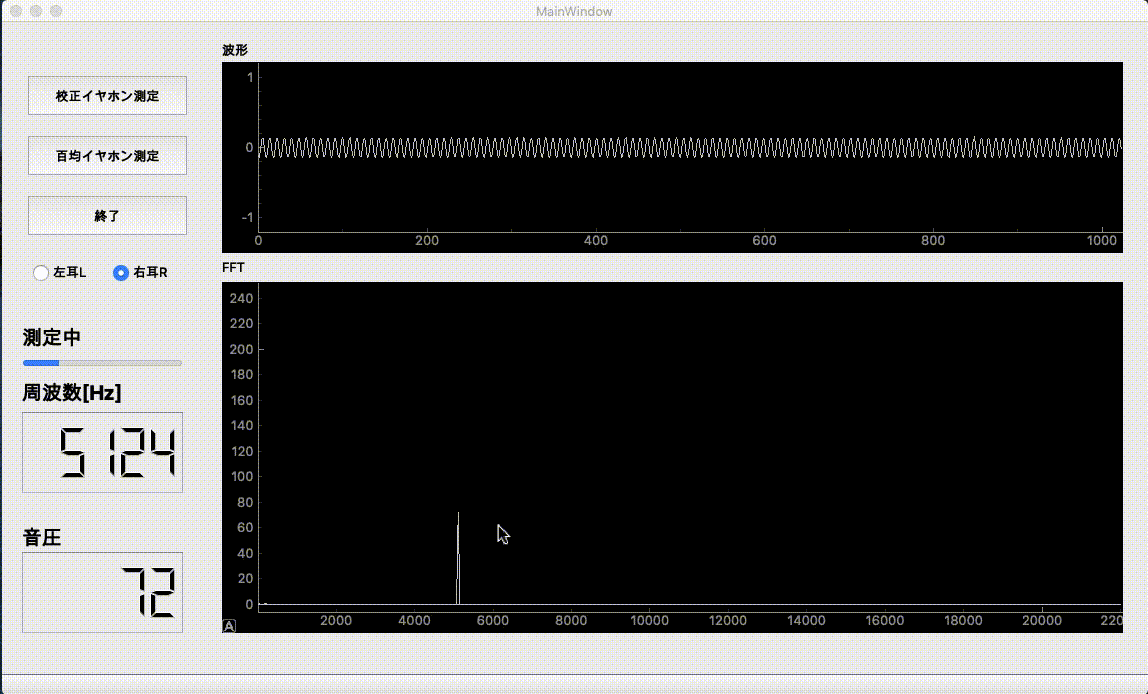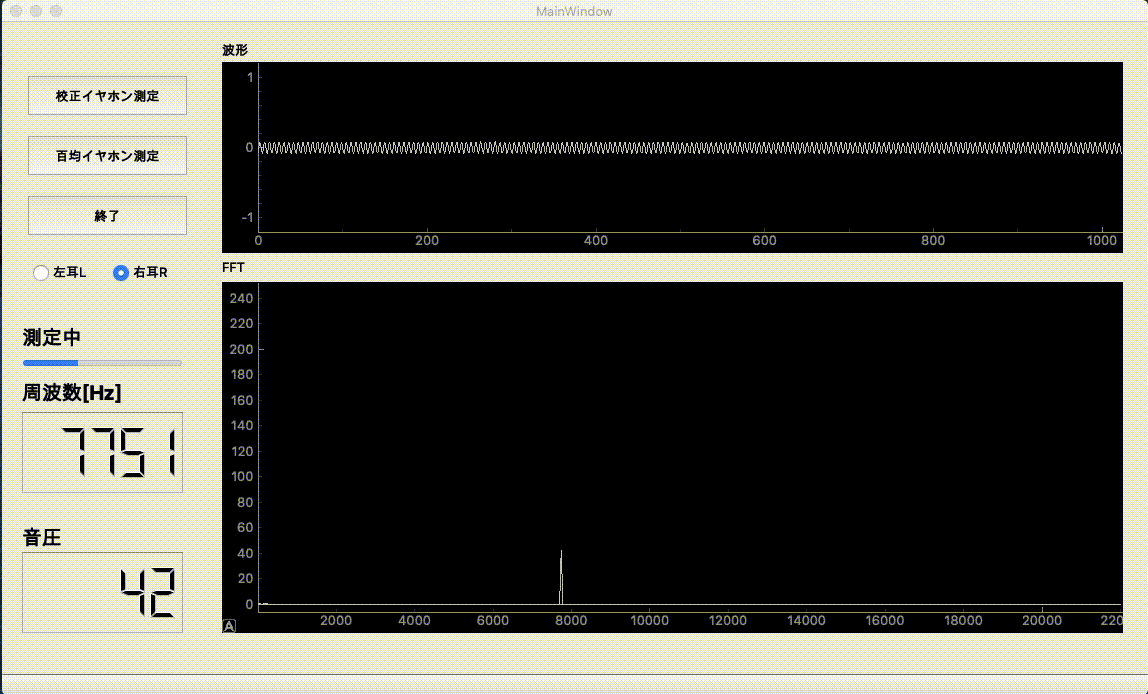
sin波の発振には自作ライブラリの
{kind=link}
を使用しています。
測定結果
仮説1、2について
測定ソフトで取得したデータを、縦軸に音量、横軸に周波数をとってmatplotlibでプロットしてみました。
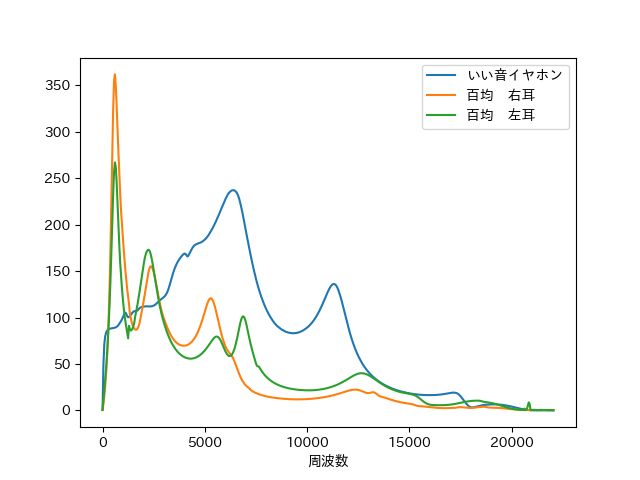
グラフを見て分かる通り、百均イヤホンの問題点は二つ。
- 言うまでもなく、周波数特性が悪い
- 右耳と左耳で出音にバラツキがある
1に関しては、低音に対して中高音域が過疎っているのがよく分かります。ですので、元の音源の低音を抑えて中高音域を上げれば、百均イヤホンからいい音が出る、はず。
2に関しては、百均イヤホンを初めて使ったときの平衡感覚が狂うような感覚(わかりませんか)の原因になっているのではないかと思います。よって元の音源のLとRで別々の変換をかけることで対処できるはず。
次に、いい音イヤホンのデータを百均のデータで割ったもの(つまり周波数ごとの倍率)を0~1に正規化したグラフです。
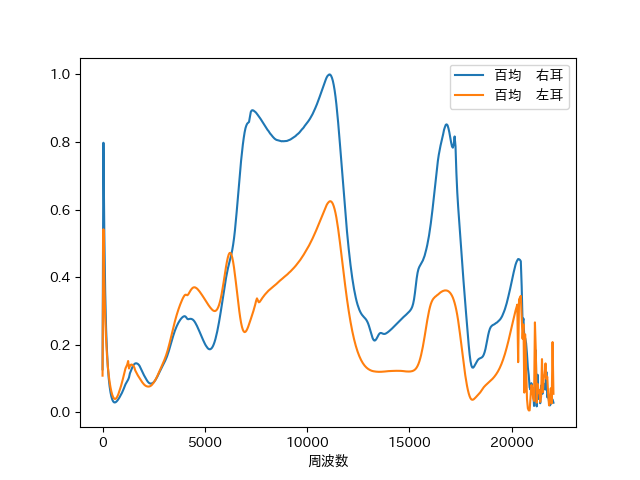
このグラフによると、例えば百均イヤホン右耳は10000Hzあたりの音を0.8倍すれば良いということがわかります。
仮説3について
仮説3の倍音に関してですが、もし倍音が発生した場合、二つ以上の山が同時に現れるはずです。しかし測定中に高調波(つまりは倍音)が観測されませんでした(あくまで目視) ですので、今回は倍音の影響は無視したいと思います。
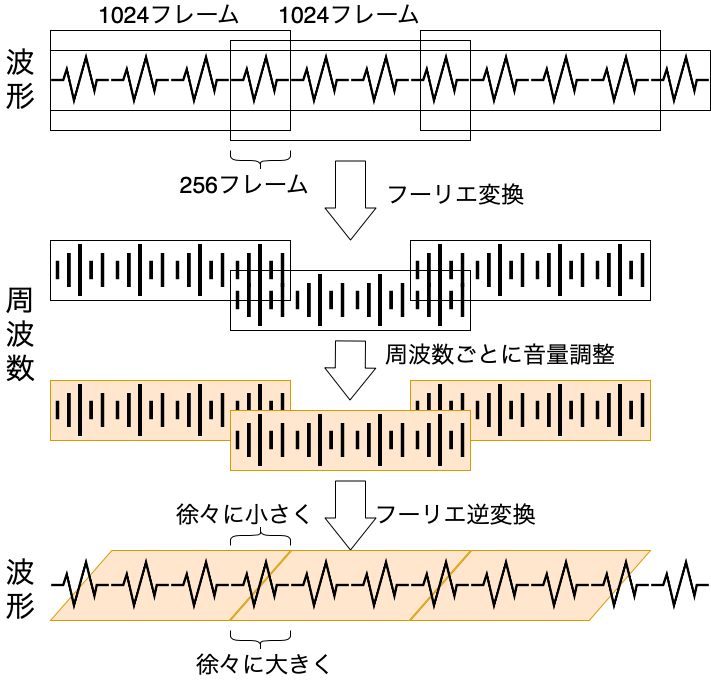
これらの実験結果をもとに、元の音源の波形を周波数領域に変換してから周波数ごとに音量を調整して、波形に戻すというプログラムの作成を目指します。
Pythonでリアルタイムイコライザーの作成
百均イヤホンをMacで常用したいので、Macの出音をリアルタイム変換できるプログラムを組んでいきます。
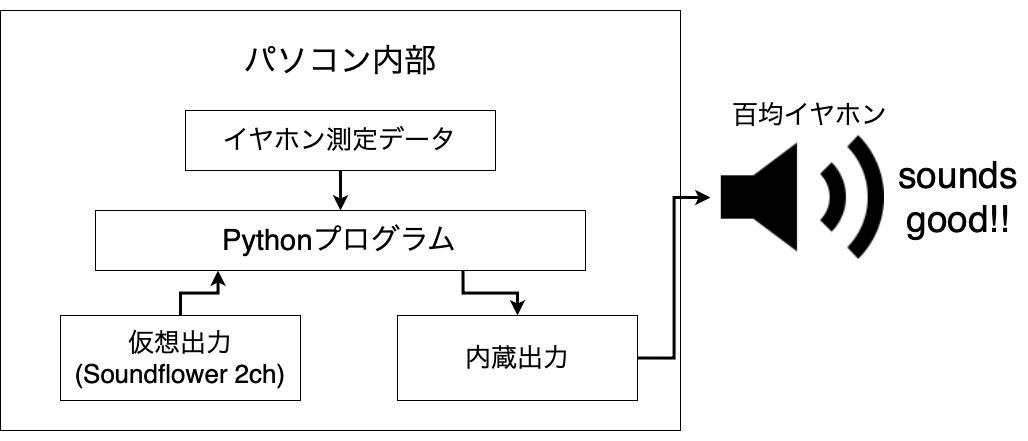
Macの音声出力を取り込むためにSoundflowerを使って仮想オーディオインターフェースを作成しました。
まず、自環境でのオーディオデバイスの割り当てを調べます。
予めpip install pyaudioでpyaudioをインストールしておきます。
import pyaudio
audio = pyaudio.PyAudio()
for x in range(0, audio.get_device_count()):
print(audio.get_device_info_by_index(x))
これを実行すると
{'index': 0, 'structVersion': 2, 'name': 'Built-in Microphone', 'hostApi': 0, 'maxInputChannels': 2, 'maxOutputChannels': 0, 'defaultLowInputLatency': 0.0029705215419501135, 'defaultLowOutputLatency': 0.01, 'defaultHighInputLatency': 0.013129251700680272, 'defaultHighOutputLatency': 0.1, 'defaultSampleRate': 44100.0}
{'index': 1, 'structVersion': 2, 'name': 'Built-in Output', 'hostApi': 0, 'maxInputChannels': 0, 'maxOutputChannels': 2, 'defaultLowInputLatency': 0.01, 'defaultLowOutputLatency': 0.0039002267573696146, 'defaultHighInputLatency': 0.1, 'defaultHighOutputLatency': 0.014058956916099773, 'defaultSampleRate': 44100.0}
〜〜〜〜〜途中略〜〜〜〜〜
{'index': 4, 'structVersion': 2, 'name': 'Soundflower (2ch)', 'hostApi': 0, 'maxInputChannels': 2, 'maxOutputChannels': 2, 'defaultLowInputLatency': 0.01, 'defaultLowOutputLatency': 0.0014512471655328798, 'defaultHighInputLatency': 0.1, 'defaultHighOutputLatency': 0.011609977324263039, 'defaultSampleRate': 44100.0}
soundflower(2ch)を入力として使うのでdevice番号は4、出力は内蔵出力ですのでdevice番号は1となります。この番号は環境によって異なります。 全ソースコードはGitHubに上げているので、ここでは一部を取り上げます。
OUTPUT_INDEX = 3
INPUT_INDEX = 4
CALIBRATE_PATH = "calibrate/earphone.npy" # Calibrate earphone data
LEFT_PATH = "earphone/L.npy" # left poor earphone
RIGHT_PATH = "earphone/R.npy" # right poor earphone
OUTPUT_FIX = 7 # change here according to sound level
RATE = 44100 # サンプリング周波数
OVERFLOW_LIMIT = 20480 # Inputのバッファーの閾値
def __init__(self, parent=None):
# pyqtのセットアップ
super(MainWindow, self).__init__(parent=parent)
self.ui = Ui_MainWindow()
self.ui.setupUi(self)
# pyaudioセットアップ
self.pa = pyaudio.PyAudio()
self.out_stream = self.pa.open(format=pyaudio.paInt16,
channels=2,
rate=self.RATE,
input=False,
output=True,
frames_per_buffer=1024,
output_device_index=self.OUTPUT_INDEX)
self.in_stream = self.pa.open(format=pyaudio.paInt16,
channels=2,
rate=self.RATE,
input=True,
output=False,
frames_per_buffer=1024,
input_device_index=self.INPUT_INDEX)
# 測定データ(ndarray)読み込み
calib = np.load(self.CALIBRATE_PATH) # いい音イヤホン
left = np.load(self.LEFT_PATH) # 百均イヤホン右
right = np.load(self.RIGHT_PATH) # 百均イヤホン左
self.FLAG = False # ON/OFFのフラグ
self.in_frames = 0
self.out_frames = 0
# 周波数ごとの倍率で最も大きい値を取得する
max = np.max([calib / left, calib / right])
# maxで割って倍率を0〜1の間に収める
self.l_mag = calib / left / max
self.r_mag = calib / right / max
# FFT用に測定データを加工
self.l_mag = np.append(
np.append(self.l_mag, [0]), self.l_mag[:0:-1]) * self.OUTPUT_FIX
self.r_mag = np.append(
np.append(self.r_mag, [0]), self.r_mag[:0:-1]) * self.OUTPUT_FIX
self.in_data = np.array([], dtype='int16')
self.l_out = np.zeros(256, dtype='int16')
self.r_out = np.zeros(256, dtype='int16')
self.up = np.linspace(0, 1, 256)
self.down = np.linspace(1, 0, 256)
# タイマーセット
self.timer = QtCore.QTimer()
self.timer.timeout.connect(self.update)
self.timer.start(10)
def update(self):
# インプットからのデータ読み込み
if self.in_stream.get_read_available() >= 1024:
input = self.in_stream.read(1024, exception_on_overflow=False)
self.in_data = np.append(
self.in_data, np.frombuffer(input, dtype='int16'))
self.in_frames += 1024
# インプットデータのフレーム数が1024を超えたら
if self.in_frames >= 1024:
left_data = self.in_data[:2047:2]
right_data = self.in_data[1:2048:2]
if self.FLAG:
left_data = np.fft.ifft(np.fft.fft(
left_data) * self.l_mag).real.astype('int16')
right_data = np.fft.ifft(np.fft.fft(
right_data) * self.r_mag).real.astype('int16')
self.l_out[-256:] = self.l_out[-256:] * \
self.down + left_data[0:256] * self.up
self.r_out[-256:] = self.r_out[-256:] * \
self.down + right_data[0:256] * self.up
self.l_out = np.append(self.l_out, left_data[256:])
self.r_out = np.append(self.r_out, right_data[256:])
self.in_data = self.in_data[1536:]
self.in_frames -= 768
self.out_frames += 768
# 出力データのフレーム数が1024を超えたら
if self.out_frames >= 1024:
data = np.array(
[self.l_out[0:1024], self.r_out[0:1024]]).T.flatten()
data = data.tolist()
data = struct.pack("h" * len(data), *data)
self.out_stream.write(data)
self.l_out = self.l_out[1024:]
self.r_out = self.r_out[1024:]
self.out_frames -= 1024
# オーバーフロー処理
if self.in_frames > self.OVERFLOW_LIMIT:
self.in_frames = 0
self.out_frames = 0
self.in_data = np.array([], dtype='int16')
self.l_out = np.zeros(256, dtype='int16')
self.r_out = np.zeros(256, dtype='int16')
print("OVER FLOW!!")
init関数でやってることはpyaudioのセットアップと測定データの加工です。
pyaudioは入力と出力のstreamを同時に開くこともできるのですが、今回入力と出力のデバイスが異なるので別々のstreamを作成しています。
また測定データの加工についてですが、波形にFFTをかけると0を対象に正負対称のスペクトルが得られるため、正部分のみの測定データを負の部分にも拡張しています。
正負対称のスペクトルが得られる理由については実数と左右対称が参考になります。
問題はupdate関数なのですが、、、だいぶ面倒な処理をしています。
インプットデータを即時加工してアウトプットすればいいと思って最初プログラムを組んだのですが、常に同じ音程のノイズが混じるため色々調べてみると、JavaScriptとWebAudioでサウンド・イコライザーを作るという記事にあるように、つなぎ目で波形がズレてノイズが生じていることが判明。 この記事を参考につなぎ目をクロスフェードさせます。
このプログラムでは1セット1024フレームのうち256フレームを隣のフレームとクロスフェードさせ、できるだけ計算量を削減しています。
Pythonでイコライザーなどを作るときに参考になれば幸いです。
そして、できたのがこのソフト。
ジャーン!!
Refine Effect!(仮名のつもりだったけど、もういいや)

とってもシンプルイズベストなUIです。さてこのソフトからどのような音が出てくるのでしょうか、、、?
結果
結論から言うと百均イヤホン高音質化に成功しました!
といってもマイク越しには伝わりにくいorz
言葉で説明すれば、エフェクトO F Fだと水中で音を聞いてる状態だったのが、エフェクトONにすると水面に顔出して周りを見渡せるぐらい視界が開ける感じです。
伝われ!
全てのソースコード、インストール方法や使い方はGitHubに上げているので、そこそこのマイクと百均イヤホンをお持ちの方は是非お試しください。